Search
Loading search results...
Search Results for "Exploiting Parallelism in Large Scale Deep Learning Model Training: Chips to Systems to Algorithms"
Exploiting Parallelism in Large Scale Deep Learning Model Training: Chips to Systems to Algorithms
Exploiting Parallelism in Large Scale DL Model Training: From Chips to Systems to Algorithms
Training LLMs at Scale - Deepak Narayanan | Stanford MLSys #83
Nvidia CUDA in 100 Seconds
TensorDash: Exploiting Sparsity to Accelerate Deep Neural Network Training
Deep Introspection for Deep Learning and Exploiting Offloading Capabilities of Bluefield Adapters
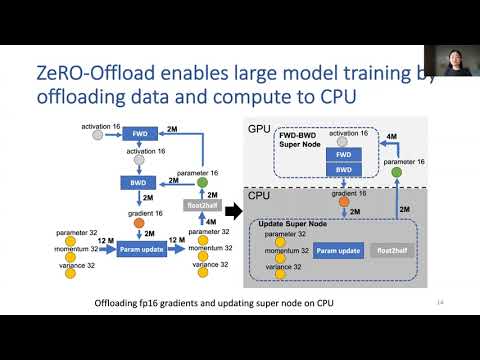
USENIX ATC '21 - ZeRO-Offload: Democratizing Billion-Scale Model Training
Tutorial: High-Performance Hardware for Machine Learning
AI Accelerator Chip Architectural Static Performance Analysis Techology
nVidia GTC'17: Building Brains - Parallelisation Strategies of large scale deep learning networks
Lecture: #16 Parallel and Distributed Deep Learning - ScaDS.AI Dresden/Leipzig
IBM Training for Bede - AI, Part 3 - Large Model Support